[DeFP]
Ranking Warnings of Static Analysis Tools Using Representation Learning
Static analysis tools are frequently used to detect potential vulnerabilities in software systems. However, an inevitable problem of these tools is their large number of warnings with a high false positive rate, which consumes time and effort for investigating. In this paper, we present DeFP, a novel method for ranking static analysis warnings. Based on the intuition that warnings which have similar contexts tend to have similar labels (true positive or false positive), DeFP is built with two BiLSTM models to capture the patterns associated with the contexts of labeled warnings. After that, for a set of new warnings, DeFP can calculate and rank them according to their likelihoods to be true positives (i.e., actual vulnerabilities). Our experimental results on a dataset of 10 real-world projects show that using DeFP, by investigating only 60% of the warnings, developers can find +90% of actual vulnerabilities. Moreover, DeFP improves the state-of-the-art approach 30% in both precision and recall. [Preprint]
Table of contents
Motivating Example
An [False Positive] Buffer Overflow warning reported by Flawfinder at line 1463 (corresponds to line 24 in the paper’s example) [Link]
....|
1186| static const char *aoc_rate_type_str(enum ast_aoc_s_rate_type value)
1187| {
1188| const char *str;
1189|
1190| switch (value) {
1191| default:
1192| case AST_AOC_RATE_TYPE_NA:
1193| str = "NotAvailable";
1194| break;
1195| case AST_AOC_RATE_TYPE_FREE:
1196| str = "Free";
1197| break;
1198| case AST_AOC_RATE_TYPE_FREE_FROM_BEGINNING:
1199| str = "FreeFromBeginning";
1200| break;
1201| case AST_AOC_RATE_TYPE_DURATION:
1202| str = "Duration";
1203| break;
1204| case AST_AOC_RATE_TYPE_FLAT:
1205| str = "Flat";
1206| break;
1207| case AST_AOC_RATE_TYPE_VOLUME:
1208| str = "Volume";
1209| break;
1210| case AST_AOC_RATE_TYPE_SPECIAL_CODE:
1211| str = "SpecialCode";
1212| break;
1213| }
1214| return str;
1215| }
....|
1442|
1443| static void aoc_s_event(const struct ast_aoc_decoded *decoded, struct ast_str **msg)
1444| {
1445| const char *rate_str;
1446| char prefix[32];
1447| int idx;
1448|
1449| ast_str_append(msg, 0, "NumberRates: %d\r\n", decoded->aoc_s_count);
1450| for (idx = 0; idx < decoded->aoc_s_count; ++idx) {
1451| snprintf(prefix, sizeof(prefix), "Rate(%d)", idx);
1452|
1453| ast_str_append(msg, 0, "%s/Chargeable: %s\r\n", prefix,
1454| aoc_charged_item_str(decoded->aoc_s_entries[idx].charged_item));
1455| if (decoded->aoc_s_entries[idx].charged_item == AST_AOC_CHARGED_ITEM_NA) {
1456| continue;
1457| }
1458| rate_str = aoc_rate_type_str(decoded->aoc_s_entries[idx].rate_type);
1459| ast_str_append(msg, 0, "%s/Type: %s\r\n", prefix, rate_str);
1460| switch (decoded->aoc_s_entries[idx].rate_type) {
1461| case AST_AOC_RATE_TYPE_DURATION:
1462| strcat(prefix, "/");
1463| strcat(prefix, rate_str);
1464| ast_str_append(msg, 0, "%s/Currency: %s\r\n", prefix,
1465| decoded->aoc_s_entries[idx].rate.duration.currency_name);
1466| aoc_amount_str(msg, prefix,
1467| decoded->aoc_s_entries[idx].rate.duration.amount,
1468| decoded->aoc_s_entries[idx].rate.duration.multiplier);
1469| ast_str_append(msg, 0, "%s/ChargingType: %s\r\n", prefix,
1470| decoded->aoc_s_entries[idx].rate.duration.charging_type ?
1471| "StepFunction" : "ContinuousCharging");
1472| aoc_time_str(msg, prefix, "Time",
1473| decoded->aoc_s_entries[idx].rate.duration.time,
1474| decoded->aoc_s_entries[idx].rate.duration.time_scale);
1475| if (decoded->aoc_s_entries[idx].rate.duration.granularity_time) {
1476| aoc_time_str(msg, prefix, "Granularity",
1477| decoded->aoc_s_entries[idx].rate.duration.granularity_time,
1478| decoded->aoc_s_entries[idx].rate.duration.granularity_time_scale);
1479| }
1480| break;
1481| case AST_AOC_RATE_TYPE_FLAT:
1482| strcat(prefix, "/");
1483| strcat(prefix, rate_str);
1484| ast_str_append(msg, 0, "%s/Currency: %s\r\n", prefix,
1485| decoded->aoc_s_entries[idx].rate.flat.currency_name);
1486| aoc_amount_str(msg, prefix,
1487| decoded->aoc_s_entries[idx].rate.flat.amount,
1488| decoded->aoc_s_entries[idx].rate.flat.multiplier);
1489| break;
1490| case AST_AOC_RATE_TYPE_VOLUME:
1491| strcat(prefix, "/");
1492| strcat(prefix, rate_str);
1493| ast_str_append(msg, 0, "%s/Currency: %s\r\n", prefix,
1494| decoded->aoc_s_entries[idx].rate.volume.currency_name);
1495| aoc_amount_str(msg, prefix,
1496| decoded->aoc_s_entries[idx].rate.volume.amount,
1497| decoded->aoc_s_entries[idx].rate.volume.multiplier);
1498| ast_str_append(msg, 0, "%s/Unit: %s\r\n", prefix,
1499| aoc_volume_unit_str(decoded->aoc_s_entries[idx].rate.volume.volume_unit));
1500| break;
1501| case AST_AOC_RATE_TYPE_SPECIAL_CODE:
1502| ast_str_append(msg, 0, "%s/%s: %d\r\n", prefix, rate_str,
1503| decoded->aoc_s_entries[idx].rate.special_code);
1504| break;
1505| default:
1506| break;
1507| }
1508| }
1509| }
....|
DeFP’s Representation Model Architecture

The above image illustrates our SA warning ranking approach. Particularly, from the source code and the set of warnings of the analyzed program, we extract the reported statements and their program slices associated with warnings. For each warning, the reported statement and the corresponding program slice are converted into vectors and then fed to the BiLSTM models to predict its likelihood to be TP. After that, all of the warnings of the program are ranked according to their predicted scores.
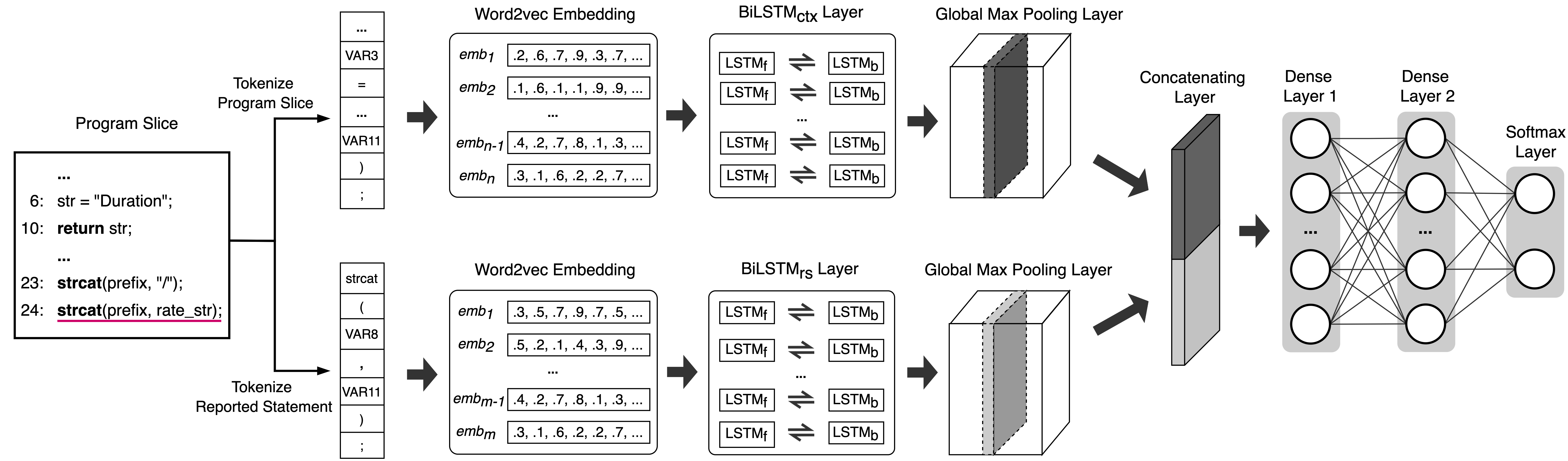
Identifier Abstraction Component
DeFP abstracts all the identifiers before feeding them to the models. In particular, variables, function names, and constants in the extracted program slices are replaced by common symbolic names. See source file to understand identifier abstraction rules.
Dataset
In order to train and evaluate an ML model ranking SA warnings, we need a set of warnings labeled to be TPs or FPs. Currently, most of the approaches are trained and evaluated by synthetic datasets such as Juliet [1] and SARD [2]. However, they only contain simple examples which are artificially created from known vulnerable patterns. Thus, the patterns which the ML models capture from these datasets could not reflect the real-world scenarios [3]. To evaluate our solution and the others on real-world data, we construct a dataset containing 6,620 warnings in 10 open-source projects [4], [5].
DOWNLOAD LINK
Read subject systems’ source files with the proper encoding to avoid misplacing warning locations
| No. | Project | Buffer Overflow | Null Pointer Dereference | ||||
|---|---|---|---|---|---|---|---|
| #W | #TP | #FP | #W | #TP | #FP | ||
| 1 | Asterisk | 2049 | 63 | 1986 | 133 | 0 | 133 |
| 2 | FFmpeg | 1139 | 387 | 752 | 105 | 37 | 68 |
| 3 | Qemu | 882 | 396 | 486 | 72 | 39 | 33 |
| 4 | OpenSSL | 595 | 53 | 542 | 9 | 2 | 7 |
| 5 | Xen | 388 | 15 | 373 | 23 | 6 | 17 |
| 6 | VLC | 288 | 20 | 268 | 16 | 2 | 14 |
| 7 | Httpd | 250 | 45 | 205 | 17 | 0 | 17 |
| 8 | Pidgin | 250 | 13 | 237 | 242 | 0 | 242 |
| 9 | LibPNG | 170 | 9 | 74 | 2 | 0 | 2 |
| 10 | LibTIFF | 74 | 9 | 65 | 3 | 3 | 0 |
| # | Total | 5998 | 1010 | 4988 | 622 | 89 | 533 |
#W, #TP and #FP are total warnings, true positives and false positives.
Experimental Results
RQ1. How accurate is DeFP in ranking SA warnings? and how is it compared to the state-of-the-art approach CNN by Lee et al. [6]?
| WN | Project | Method | # TP warnings found in top-k% warnings | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Top-5% | Top-10% | Top-20% | Top-50% | Top-60% | ||||||||
| Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall | |||
| BO | Qemu | DeFP | 82.22% | 9.34% | 67.78% | 15.40% | 65.14% | 28.78% | 52.27% | 58.08% | 50.38% | 67.43% |
| CNN | 71.11% | 8.09% | 53.33% | 12.13% | 46.86% | 20.72% | 44.32% | 49.25% | 43.02% | 57.57% | ||
| FFmpeg | DeFP | 67.27% | 9.56% | 61.74% | 18.34% | 52.43% | 31.00% | 38.95% | 57.37% | 37.72% | 66.66% | |
| CNN | 30.91% | 4.40% | 31.30% | 9.30% | 33.24% | 19.64% | 32.46% | 47.80% | 33.04% | 58.39% | ||
| Asterisk | DeFP | 34.00% | 53.97% | 18.54% | 60.26% | 10.73% | 70.00% | 5.18% | 84.10% | 4.56% | 88.97% | |
| CNN | 11.00% | 17.56% | 8.78% | 28.59% | 7.56% | 49.36% | 4.49% | 72.95% | 3.82% | 74.49% | ||
| COMBINED | DeFP | 66.00% | 19.60% | 56.00% | 33.27% | 43.92% | 52.18% | 27.50% | 81.68% | 24.82% | 88.42% | |
| CNN | 43.00% | 12.77% | 39.67% | 23.56% | 34.25% | 40.69% | 25.40% | 75.45% | 23.46% | 83.56% | ||
| NPD | COMBINED | DeFP | 80.00% | 26.93% | 65.00% | 43.66% | 47.20% | 66.14% | 25.81% | 89.74% | 22.58% | 94.25% |
| CNN | 63.33% | 21.37% | 43.33% | 29.15% | 38.40% | 53.99% | 21.29% | 74.25% | 19.62% | 82.09% | ||
RQ2. How does the extracted warning context affect DeFP’s performance?
| WN | Project | Method | # TP warnings found in top-k% warnings | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Top-5% | Top-10% | Top-20% | Top-50% | Top-60% | ||||||||
| Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall | |||
| BO | COMBINED | RAW | 47.00% | 13.96% | 39.83% | 23.66% | 32.92% | 39.11% | 24.30% | 72.18% | 22.71% | 80.89% |
| CD | 58.00% | 17.23% | 40.50% | 24.06% | 25.25% | 30.00% | 19.83% | 58.91% | 20.96% | 74.65% | ||
| DD | 48.00% | 14.26% | 42.33% | 25.15% | 34.92% | 41.49% | 25.03% | 74.36% | 23.10% | 82.28% | ||
| CD & DD | 66.00% | 19.60% | 56.00% | 33.27% | 43.92% | 52.18% | 27.50% | 81.68% | 24.82% | 88.42% | ||
| NPD | COMBINED | RAW | 40.00% | 13.40% | 48.33% | 32.42% | 36.80% | 51.57% | 23.55% | 81.90% | 20.98% | 87.65% |
| CD | 43.33% | 14.71% | 36.67% | 24.84% | 35.20% | 49.41% | 24.52% | 85.36% | 20.70% | 86.47% | ||
| DD | 70.00% | 23.40% | 51.67% | 34.58% | 40.80% | 57.19% | 24.84% | 86.47% | 22.04% | 92.09% | ||
| CD & DD | 80.00% | 26.93% | 65.00% | 43.66% | 47.20% | 66.14% | 25.81% | 89.74% | 22.58% | 94.25% | ||
RAW, CD, DD, and CD && DD denote the warning contexts which are captured by raw source code, program slices on control dependencies, program slices on data dependencies, and program slices on both control and data dependencies, respectively.
RQ3. How does the highlighting reported statement (RP) impact the performance of DeFP?
| WN | Project | Method | # TP warnings found in top-k% warnings | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Top-5% | Top-10% | Top-20% | Top-50% | Top-60% | ||||||||
| Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall | |||
| BO | COMBINED | W/O RP | 59.00% | 17.52% | 54.50% | 32.38% | 41.00% | 48.71% | 26.83% | 79.70% | 24.43% | 87.03% |
| With RP | 66.00% | 19.60% | 56.00% | 33.27% | 43.92% | 52.18% | 27.50% | 81.68% | 24.82% | 88.42% | ||
| NPD | COMBINED | W/O RP | 70.00% | 23.66% | 55.00% | 37.12% | 42.40% | 59.61% | 23.55% | 82.03% | 19.90% | 83.20% |
| With RP | 80.00% | 26.93% | 65.00% | 43.66% | 47.20% | 66.14% | 25.81% | 89.74% | 22.58% | 94.25% | ||
RQ4. How does the identifier abstraction (IA) component impact the performance of DeFP?
| WN | Project | Method | # TP warnings found in top-k% warnings | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Top-5% | Top-10% | Top-20% | Top-50% | Top-60% | ||||||||
| Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall | |||
| BO | COMBINED | W/O IA | 62.33% | 18.51% | 49.00% | 29.11% | 39.83% | 47.33% | 27.07% | 80.40% | 24.54% | 87.43% |
| With IA | 66.00% | 19.60% | 56.00% | 33.27% | 43.92% | 52.18% | 27.50% | 81.68% | 24.82% | 88.42% | ||
| NPD | COMBINED | W/O IA | 56.67% | 19.15% | 48.33% | 32.75% | 41.60% | 58.43% | 24.84% | 86.54% | 22.85% | 95.56% |
| With IA | 80.00% | 26.93% | 65.00% | 43.66% | 47.20% | 66.14% | 25.81% | 89.74% | 22.58% | 94.25% | ||
References
[1] V. Okun, A. Delaitre, P. E. Black et al., “Report on the static analysis tool exposition (sate) iv,” NIST Special Publication, vol. 500, p. 297, 2013.
[2] N. I. of Standards and Technology, “Software assurance reference dataset.” [Online]. Available: https://samate.nist.gov/SRD/index.php
[3] S. Chakraborty, R. Krishna, Y. Ding, and B. Ray, “Deep learning based vulnerability detection: Are we there yet,” IEEE Transactions on Software Engineering, 2021.
[4] Y. Zhou, S. Liu, J. Siow, X. Du, and Y. Liu, “Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks,” arXiv preprint arXiv:1909.03496, 2019.
[5] G. Lin, W. Xiao, J. Zhang, and Y. Xiang, “Deep learning-based vulnerable function detection: A benchmark,” in International Conference on Information and Communications Security. Springer, 2019, pp. 219– 232.
[6] S. Lee, S. Hong, J. Yi, T. Kim, C.-J. Kim, and S. Yoo, “Classifying false positive static checker alarms in continuous integration using convolutional neural networks,” in 2019 12th IEEE Conference on Software Testing, Validation and Verification (ICST). IEEE, 2019, pp. 391–401.
Cite us
@inproceedings{ngo2021ranking,
title={Ranking Warnings of Static Analysis Tools Using Representation Learning},
author={Ngo, Kien-Tuan and Do, Dinh-Truong and Nguyen, Thu-Trang and Vo, Hieu Dinh},
booktitle={2021 28th Asia-Pacific Software Engineering Conference (APSEC)},
pages={327--337},
year={2021},
organization={IEEE}
}